Edit: Updated the dead links.
I don't wanna read all this, give me the real meat. GIVE ME THE OLLAMA IPS! Fine, here's the list:
- ~17k IPs running on default port 11434 (you will most likely be able to use any random instance from here)
- ~113k IPs running on non-default ports (you might not be so lucky with random IPs from the list)
After you select the IPs, just set OLLAMA_HOST to that IP and then just use the ollama cli as usual.
$ OLLAMA_HOST=<IP> ollama run mistral:7b
Ollama by default comes with no authentication support. Couple it with docker's horrible choice of publishing at 0.0.0.0 by default gives us an ample of public ollama instances that you can use for free inference!
According to censys, one of many shodan-like search engine, there are 74k ollama instances open to public:
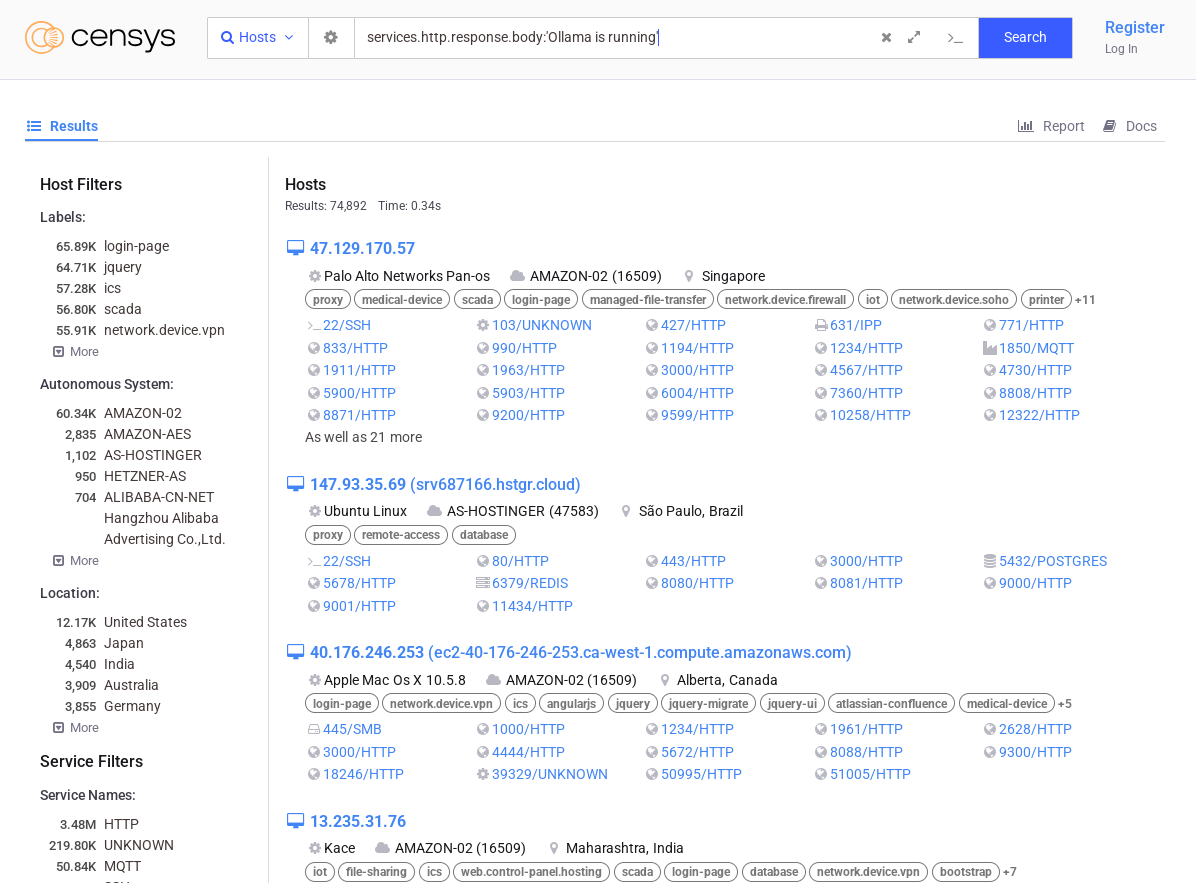
After creating a quick and dirty script using one of the ollama instance, and using the shodan API, I was able to scrape around 113k instances:

Unfortunately, most of the instances running on non-default port don't really work right out of the box. Most of them give out gibberish output whenever you try to run a model.
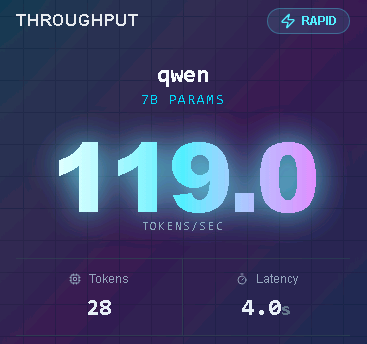
In most of the instances, I usually got around 100-150 tokens/s which is pretty good:
Anyway, there you go. GO NUTS!